聚类算法
文章目录
聚类
之前讲过如何利用 tensorflow 的模型比较句子的相似度,最后得到了相似度矩阵,那得到了相似度矩阵之后如何判定哪些应该归为一类,也就是说哪些句子的含义是相似的?
这里我们会用到聚类算法,顾名思义,就是将相同的类别归到一起,是一种无监督机器学习任务,那会有哪些聚类算法呢?
- 亲和力传播
- 聚合聚类
- BIRCH
- DBSCAN
- K-均值
- Mini-Batch K-均值
- Mean Shift
- OPTICS
- 光谱聚类
- 高斯混合模型
这些方法都可以在 Python 库sklearn中有提供,如下图

官网还提供了各个聚类算法的图形化表示,并进行比较
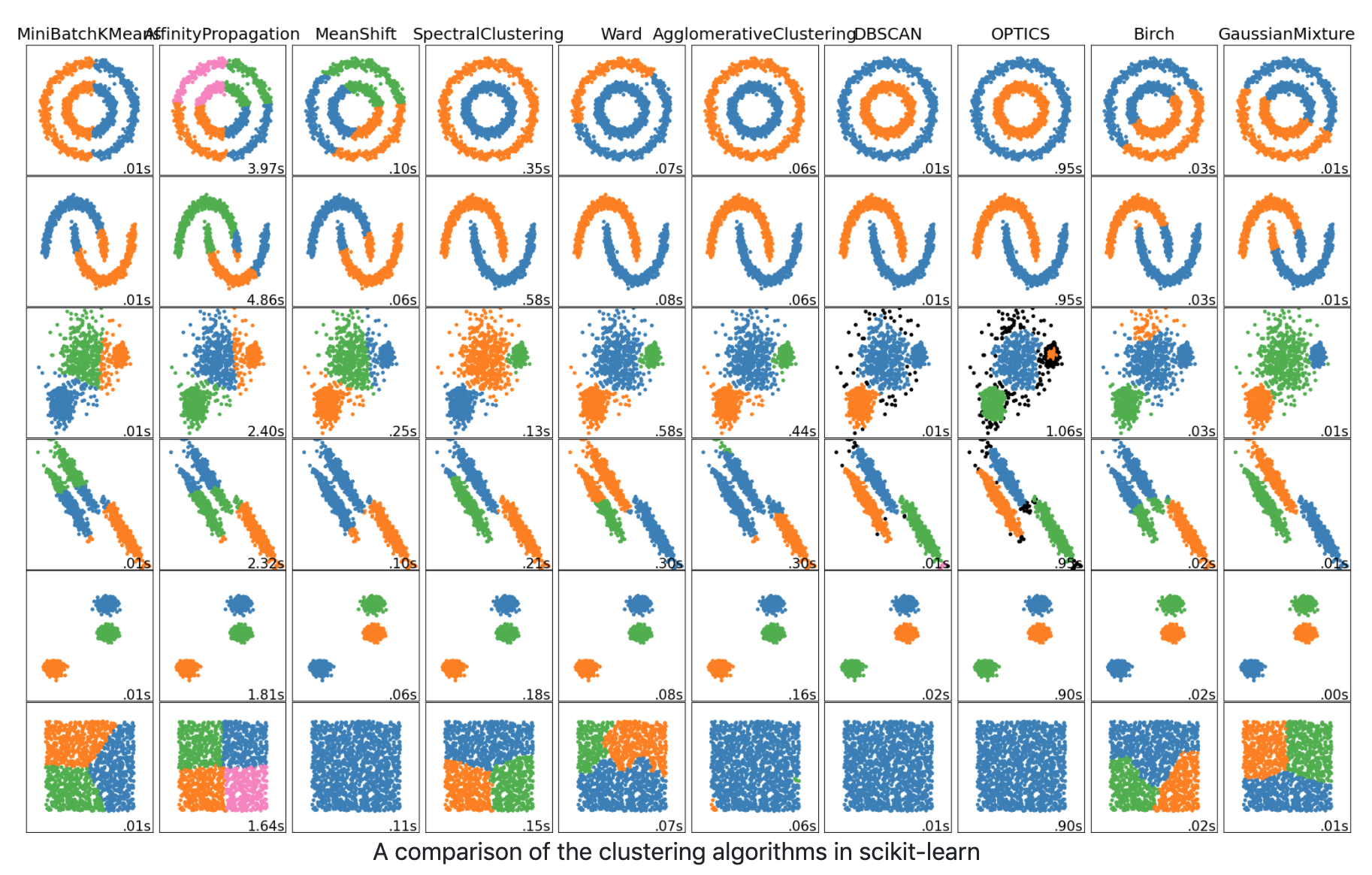
具体可以看官方文档,后续会补充每个聚类算法的代码示例,waiting
官方文档
https://scikit-learn.org/stable/modules/clustering.html#clustering
http://lijiancheng0614.github.io/scikit-learn/modules/classes.html
https://stackoverflow.com/questions/30089675/clustering-cosine-similarity-matrix/30093501#30093501 https://zhuanlan.zhihu.com/p/126661239
文章作者 Brook
上次更新 2020-08-21