Logstash
文章目录
安装
安装 Logstash 的话首先需求确认下本机的环境,需要 Java 8 或者 Java 11。 可以通过以下命令检查本机的java环境:
java -version
如果系统又安装java并配置了环境变量,那么会看到如下输出:
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
下载地址
也可以通过命令行直接安装,下面进行介绍
APT
下载并安装公共签名密钥:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
在执行这个之前,你可能需要安装 apt-transport-https 包在 Debian 系统上
sudo apt-get install apt-transport-https
将仓库添加 /etc/apt/sources.list.d/elastic-7.x.list 下:
echo “deb https://artifacts.elastic.co/packages/7.x/apt stable main” | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
然后执行更新仓库并安装 logstash
sudo apt-get update && sudo apt-get install logstash
想以系统服务的形式进行运行,可以参考:https://www.elastic.co/guide/en/logstash/7.7/running-logstash.html
YUM
下载并安装公钥:
sudo rpm –import https://artifacts.elastic.co/GPG-KEY-elasticsearch
添加一下内容到目录 /etc/yum.repos.d/ 下,以 .repo 作为后缀,如 logstash.repo
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
完成之后你就可以进行安装了
sudo yum install logstash
Homebrew
需要用 HomeBrew 进行安装,首先需要将 elastic 仓库添加到 HomeBrew 中
brew tap elastic/tap
添加之后可以执行如下命令进行安装:
brew install elastic/tap/logstash-full
通过 HomeBrew 进行启动:
brew services start elastic/tap/logstash-full
在前台运行,直接执行:
logstash
安装参考
https://www.elastic.co/guide/en/logstash/current/installing-logstash.html
管道介绍
当安装完 logstash 之后,我们需要去配置从哪里读取数据,之后转换成什么数据格式输出到什么地方去,这里就会涉及到logstash中两个必须的元素:input 和 output,还有一个可选的 filter
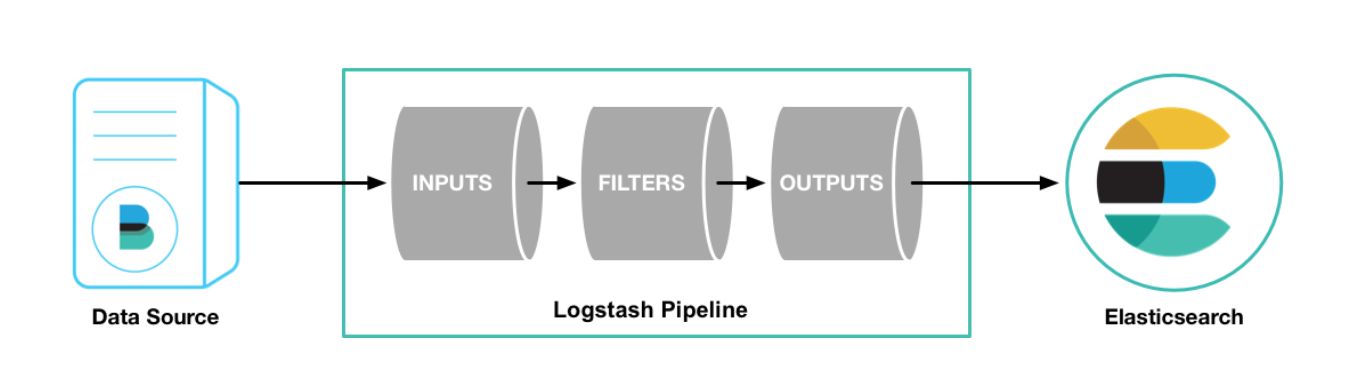
为了验证 logstash 的安装,可以运行如下最基础的管道配置:
cd logstash-7.6.2
bin/logstash -e 'input { stdin { } } output { stdout {} }'
其中 -e 参数用于指定命令行的配置,示例中接收标准的输入 stdin ,并以 stdout 标准输出.
参考
https://www.elastic.co/guide/en/logstash/current/first-event.html
配置介绍
logstash.yml
这个配置文件是所有配置的入口文件,包括对 pipeline 的基础配置,还有 pipeline config 的配置等,目前Demo只配置了 pipeline 的配置文件的路径,如下:
# ------------ Pipeline Configuration Settings --------------
#
# Where to fetch the pipeline configuration for the main pipeline
#
path.config: /Users/work/bin/logstash-7.6.2/pipconfig/*.conf
path.config 用于配置 pipeline 配置文件的路径,可以根据不同的业务需求,写不同的配置文件,还是比较方便的。下面主要介绍这个配置文件相关操作。
pipeline conf
上面讲到到过管道,这个文件就是用于配置管道的,毕竟真实环境需要永久性的配置来保证服务的正常运行,那数据从哪里读取(input),需要过滤成什么样的数据(filter),转换之后数据需要输出到哪里(output),当知道了这些概念之后就好办了,下面对管道里面这几个插件进行介绍,首先可以先看下我自己的一份将本地日志文件转换成结构化数据存储到 elasticsearch 中的配置。
日志格式样例如下:
DEBUG: 20-06-18 20:46:06 [/home/work/odp/app/xxx/xxx/xxx/xxxx.php:198] errno[0] logId[2766595684] module[xxxx] spanid[0] force_sampling[0] uri[/api/xxxx] refer[] cookie[] client_ip[10.216.189.154] local_ip[10.252.15.11] product[xxx] subsys[update] module[xxx] uniqid[0] cgid[39604] uid[0] optime[1592480766.968] elastic:voice_query:{"query":"今日の天気は","intent":"query_weather","date":"2020-06-18 20:46:06","uid":"2883727343","source":"1","tv":"0"}
这是一份混合的日志输出,包含正常的日志输出,也包含 json 数据,那我们需要把这里的 json 数据发送到 es 中进行统计检索,并将日志中的时间转换为对应的 timestamp ,需要如何进行配置呢?
input {
file {
path => "/home/work/log/app/xxxxx/access.log.20200[6,7,8,9]*"
start_position => "beginning"
type => "voice_query"
}
}
filter {
grok {
match => { "message" => "DEBUG: %{TIMESTAMP_ISO8601:log_time} %{DATA:loginfo} elastic:voice_query:%{GREEDYDATA:data}" }
}
if ![data] {
drop{}
}
json {
source => "data"
}
mutate {
remove_field => "message"
}
date {
match => ["log_time", "yy-MM-dd HH:mm:ss"]
}
mutate {
remove_field => "log_time"
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.1:9201"]
index => "voice_query_%{+YYYY.MM.dd}"
}
}
看到这份配置,是不是看到了刚才所说的 input filter output 了,那下面对这三个插件进行介绍。
input插件
用于配置数据来源,那么可以配置哪些来源呢?
- 标准输入(Stdin)
- 读取文件(File)
- 读取网络数据(TCP)
- 自动生成测试数据(Generator)
- 读取 Syslog 数据
- 读取 Redis 数据
- 读取 Collected 数据
示例中配置的是 file ,用于读取日志文件的数据,这是经常会使用的输入类型,里面具体的配置就不讲了,大家可自行查看官方文档,里面有更详细的介绍。
filter 插件
这个插件主要用于数据转换,将非结构化的数据转换成结构化的数据,这里面会涉及到正则匹配过滤,主要是 grok 的配置,这里可以提供下官方的工具进行配合编写,提高效率。
官方预设的正则字段
Grok 在线调试
这对于编写过滤来说真的是受益颇多,真的是事半功倍的一款工具,力荐。
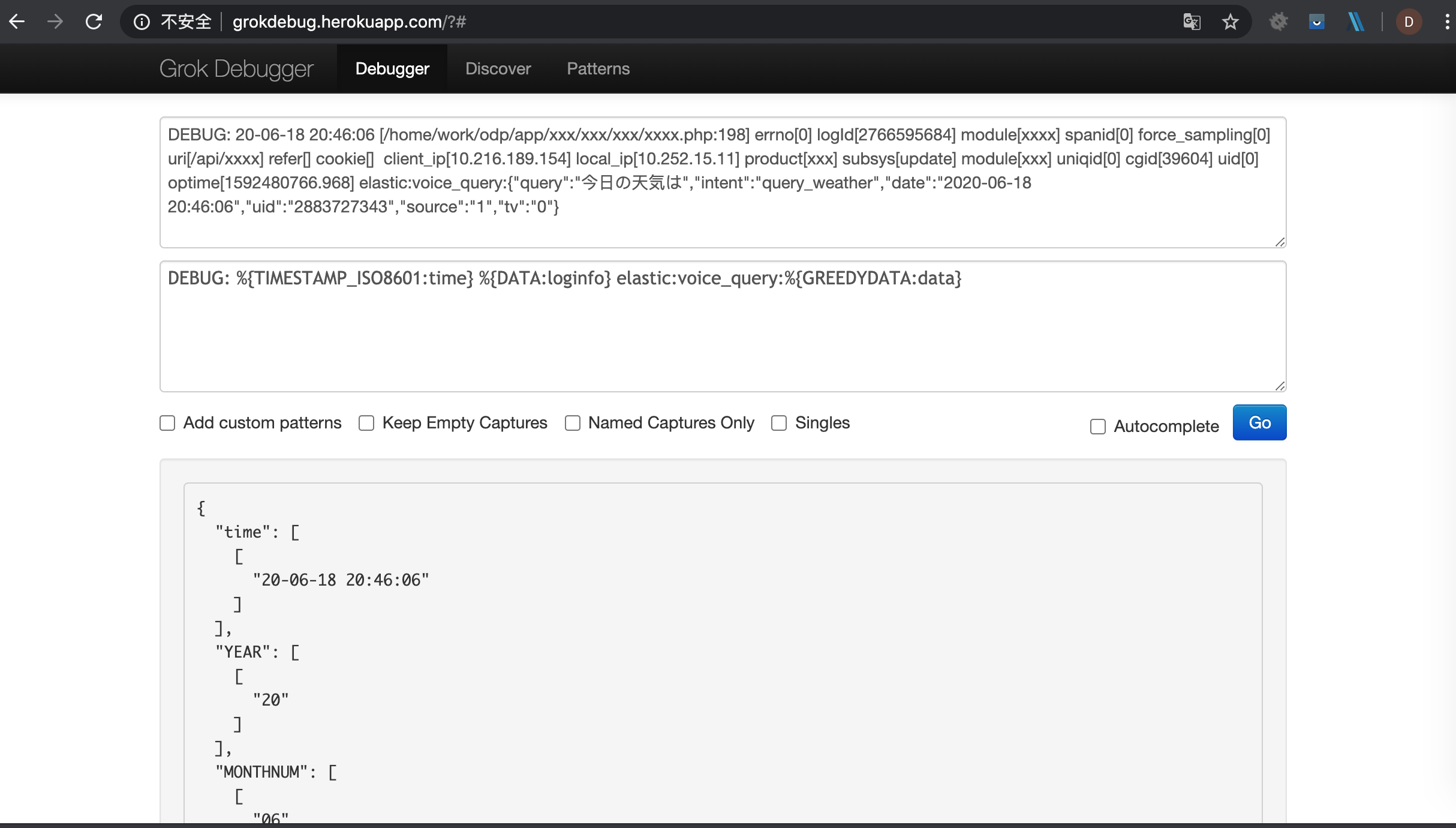
这里面还有个很重要的就是对于时间的处理,因为想在 kibana 中通过 timestamp 进行日志查看,那就需要将日志中的时间映射到 内部 timestamp 上,主要是如下配置:
date {
match => ["log_time", "yy-MM-dd HH:mm:ss"]
}
mutate {
remove_field => "log_time"
}
要非常注意 log_time 中时间的格式化,一定要和日志中的保持一致,否则时间会有问题。
output插件
很显然这个是用来配置输出的,经过filter处理之后,需要将处理的数据输出到哪里,就是在这里面配置的。
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.1:9201"]
index => "voice_query_%{+YYYY.MM.dd}"
}
}
输出到 elasticsearch 中的配置。
更新配置
bin/logstash -f apache.config --config.reload.automatic
通过启动的时候添加如上参数,可以在config变更时自动进行加载
如果logstash已经启动,则可以通过以下命令进行强制关闭
kill -SIGHUP 14175
其中 14175 是进程号
通过kibana看数据
运行 logstash,在 es 中创建完索引后,通过kibana 可视化查看数据如下:
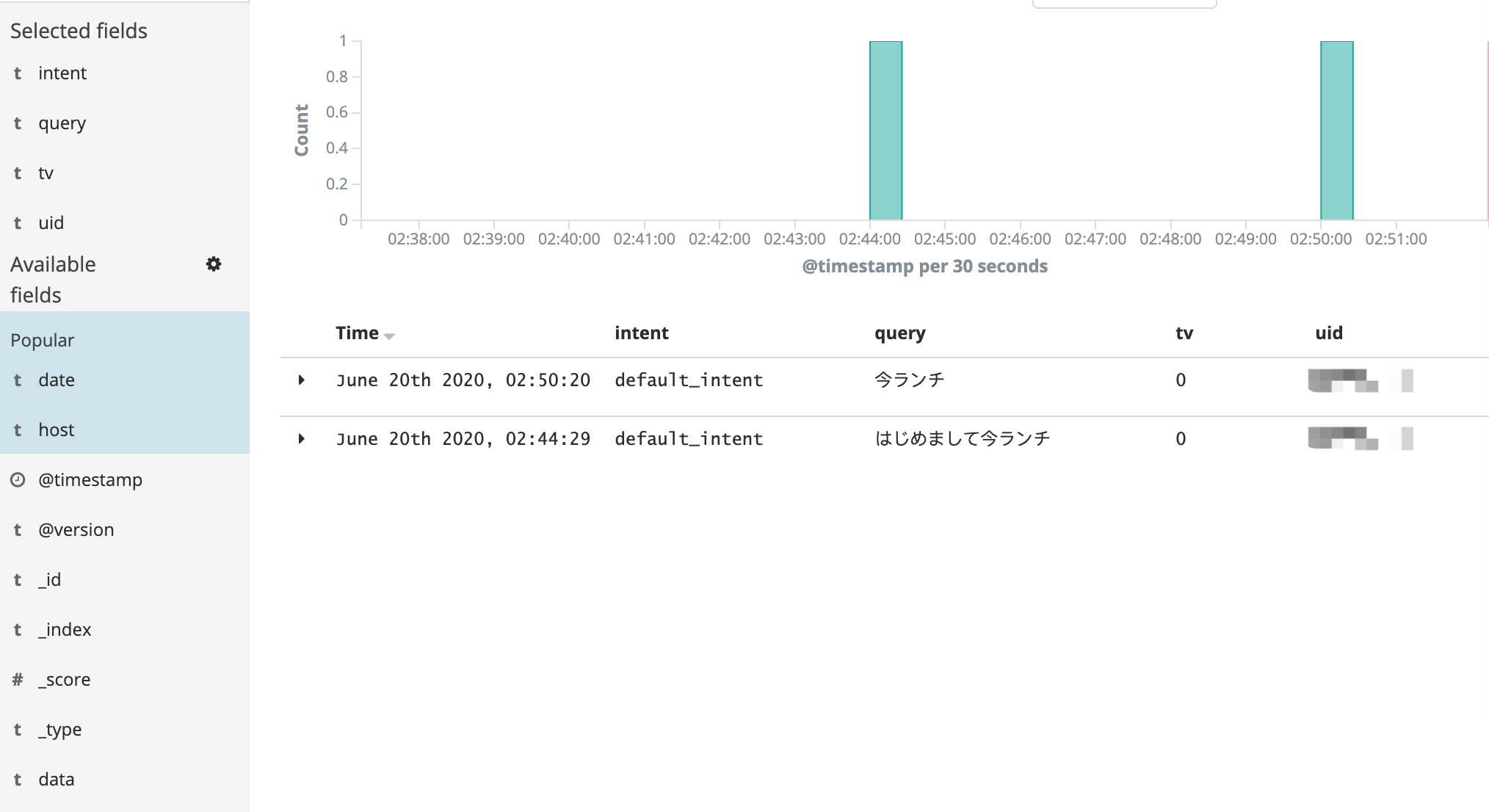
至此,数据导入到显示就结束了,当然这只是开始,还会有一些性能相关的配置,这个后续再写了。
参考
在实践过程中有一份很不错的参考文档,讲得很详细。
http://doc.yonyoucloud.com/doc/logstash-best-practice-cn/index.html
利用 logstash 收集 nginx 日志示例:
文章作者 Brook
上次更新 2020-06-18